I. Introduction▲
L'Audio Engineering Society (AES) et l'European Broadcasting Union (EBU) ont ûˋtabli conjointement une norme audio numûˋrique connue sous le terme d'interface AES/EBU. Cette norme propose des formats pour l'ûˋchange d'informations audionumûˋriques entre appareils audio professionnels, tout en garantissant la souplesse nûˋcessaire aux applications spûˋciales. L'International Electrotechnical Commission (IEC) a ûˋgalement adoptûˋ un format basûˋ sur la norme AES/EBU pour les appareils audio grand public.
En bref, la norme de format AES/EBU dûˋfinit comment deux canaux d'informations audio sont pûˋriodiquement ûˋchantillonnûˋs et transmis sur une paire de fils torsadûˋs. Les canaux audio gauche et droit sont multiplexûˋs et sont autocadencûˋs et autosynchronisûˋs. Le format de mesure est indûˋpendant de la frûˋquence d'ûˋchantillonnage recommandûˋe par l'AES et supporte, sur 24 bits, 32 kHz, 44,1 kHz et 48 kHz.
ô¨ô Ne jamais transmettre ce que l'on ne peut pas entendre.ô ô£
Cette compression audio, qui est entiû´rement basûˋe sur les caractûˋristiques de l'audition humaine, s'accompagne de pertes et ne peut ûˆtre abordûˋe sans une ûˋtude prûˋalable de ce sens. Il est surprenant de constater que l'audition humaine, et particuliû´rement en stûˋrûˋo, a un pouvoir discriminatoire bien supûˋrieur û celui de la vision et c'est pourquoi la compression audio doit ûˆtre envisagûˋe avec encore plus de prûˋcautions. Comme la compression vidûˋo, la compression audio nûˋcessite plusieurs niveaux de complexitûˋ en fonction du facteur de compression souhaitûˋ.
Une autre considûˋration importante dans l'enregistrement et la diffusion numûˋrique d'aujourd'hui est le monitoring du ô¨ô point de crashô ô£ ou point d'atteinte du ô¨ô niveau d'entrûˋe maximumô ô£ admissible par un systû´me ou un ûˋquipement. Le format d'enregistrement numûˋrique est quelque peu plus tolûˋrant, dans le sens oû¿ quelques pointes ô¨ô hors tolûˋranceô ô£ tombent simplement hors de la gamme de l'appareil numûˋrique et ne sont pas ûˋchantillonnûˋes. Une sûˋrie de ô¨ô popsô ô£ ou de ô¨ô sifflementsô ô£ qui pourraient sûˋrieusement compromettre un enregistrement analogique peuvent ûˆtre automatiquement ô¨ô attûˋnuûˋsô ô£. Ce phûˋnomû´ne a entraûÛnûˋ quelques personnes vers la fausse notion que les niveaux audio numûˋriques pouvaient ûˆtre apprûˋhendûˋs de maniû´re plus simpliste. Les appareils de mesure rudimentaires intûˋgrûˋs dans la plupart des appareils numûˋriques reflû´tent cette attitude. Il est aussi nûˋcessaire de produire un volume plus consistant dans les enregistrements numûˋriques que dans les enregistrements analogiques. Avoir quelques prises ô¨ô plus fortesô ô£ que d'autres est plus acceptable dans le nouveau monde numûˋrique que cela n'ûˋtait dans l'environnement analogique. Il y a ûˋgalement la mûˆme nûˋcessitûˋ de protûˋger les CRûTES. L'idûˋe qu'un ô¨ô certain nombreô ô£ de crashs soit tolûˋrable est simplement fausse. Obtenir le volume au dûˋtriment des crûˆtes rûˋsulte en une perte de dimension et de clartûˋ.
II. Le mûˋcanisme de l'audition▲
L'audition se compose d'un processus physique û l'intûˋrieur de l'oreille et d'un processus nerveux et mental qui se combinent pour donner une impression sonore. L'impression que nous recevons n'est pas exactement similaire û la forme d'onde acoustique prûˋsente dans le conduit auditif parce qu'une certaine entropie est perdue. Les systû´mes de compression audio qui donneront de bons rûˋsultats seront donc ceux qui ne perdront que la partie de l'entropie qui est perdue dans le mûˋcanisme de l'audition.
Le mûˋcanisme physique de l'audition se rûˋpartit en trois partiesô : l'oreille externe, l'oreille moyenne et l'oreille interne. En plus du pavillon, l'oreille externe comprend le conduit auditif et le tympan. Le tympan transforme les sons incidents en une vibration comme le fait un diaphragme de microphone. L'oreille interne opû´re en utilisant ces vibrations transmises û travers un fluide. L'impûˋdance du fluide est bien supûˋrieure û celle de l'air et l'oreille moyenne agit comme un transformateur d'impûˋdance qui effectue le transfert d'ûˋnergie.
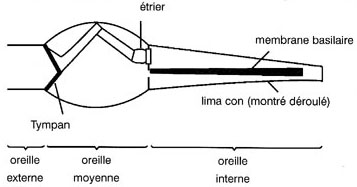
On voit ci-dessus que les vibrations sont transfûˋrûˋes û l'oreille interne par l'ûˋtrier, qui agit sur la fenûˆtre ovale. Les vibrations du fluide de l'oreille interne parviennent au limaûÏon, une cavitûˋ du crûÂne en forme de spirale(prûˋsentûˋe dûˋroulûˋe sur la figure, pour plus de clartûˋ). La membrane basilaire est ûˋtirûˋe sur toute la longueur du limaûÏon. Le poids et la consistance de cette membrane varient d'un bout û l'autre. Prû´s de la fenûˆtre ovale, la membrane est rigide et lûˋgû´re et sa frûˋquence de rûˋsonance est ûˋlevûˋe. û l'autre extrûˋmitûˋ, la membrane est lourde et souple, ce qui fait qu'elle rûˋsonne aux frûˋquences basses.
La gamme de frûˋquences disponibles dûˋtermine la plage de l'audition humaine qui, pour la plupart des gens, s'ûˋtend de 60 Hz û 15 Khz. Les diffûˋrentes frûˋquences du son incident provoquent la vibration de diffûˋrentes parties de la membrane. Toutes les zones de la membrane sont reliûˋes û diffûˋrentes terminaisons nerveuses qui permettent une discrimination trû´s fine. La membrane basilaire est ûˋgalement munie de fins muscles commandûˋs par les nerfs et qui agissent ensemble dans une sorte de contre-rûˋaction positive qui aurait tendance û augmenter le facteur de rûˋsonance Q. Le comportement rûˋsonnant de la membrane basilaire constitue une rûˋplique exacte d'un analyseur de transformûˋes.
En raison de la thûˋorie de l'incertitude, plus le domaine de frûˋquences d'un signal est connu, moins son domaine temporel est connu. En consûˋquence, plus un systû´me est apte û dûˋterminer la diffûˋrence entre deux frûˋquences, moins il est capable de sûˋparer le temps qui les sûˋpare. L'audition humaine a dûˋveloppûˋ un certain compromis entre la discrimination incertitude temporelle et la discrimination de frûˋquence, ce compromis impliquant qu'aucune perfection n'est atteinte. La discrimination imparfaite de frûˋquences rûˋsulte du fait de l'incapacitûˋ de sûˋparer deux frûˋquences proches. Cette incapacitûˋ est connue comme un effet de masquage auditif qui rûˋduit la sensibilitûˋ d'un son en prûˋsence d'un autre. La figure 3.2a montre que le seuil d'audition est fonction de la frûˋquence. La plus grande sensibilitûˋ se situe naturellement dans la gamme de frûˋquences de la parole.
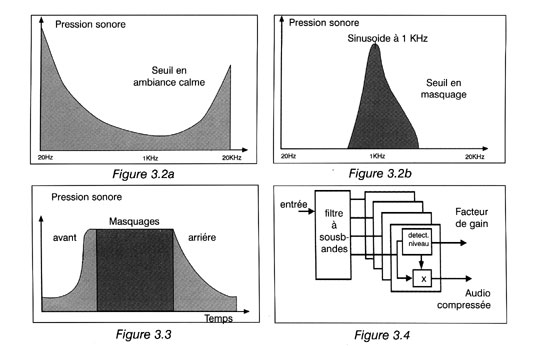
En prûˋsence d'une note pure, le seuil est modifiûˋ, tel qu'indiquûˋ sur la figure 3.2b. Le seuil est relevûˋ non seulement pour des frûˋquences hautes, mais aussi pour quelques frûˋquences basses. En prûˋsence d'une source sonore au spectre plus complexe, comme de la musique, le seuil est relevûˋ û presque toutes les frûˋquences. Une consûˋquence de ce comportement est que le sifflement d'une cassette audio n'est audible que pendant les passages trû´s doux de la musique.
La compression utilise ce principe en amplifiant les frûˋquences basses avant l'enregistrement ou la transmission et en les ramenant ultûˋrieurement û leur niveau convenable. La discrimination imparfaite de temps montrûˋe par l'oreille est due û sa rûˋponse rûˋsonante. Le facteur de rûˋsonance Q est tel qu'il faut qu'un son donnûˋ soit prûˋsent au moins une milliseconde avant qu'il ne devienne audible. û cause de cette rûˋponse lente, le masquage peut se produire mûˆme si les deux signaux concernûˋs ne sont pas simultanûˋs. Les masquages avant et arriû´re peuvent se produire quand le son de masquage continue û agir û des niveaux plus faibles avant et aprû´s la durûˋe courante du son de masquage. La figure 3.3 dûˋmontre ce concept. Le masquage relû´ve le seuil d'audition et les systû´mes de compression tirent parti de cet effet en rehaussant le niveau ô¨ô plancherô ô£ de bruit, permettant ainsi au signal audio d'ûˆtre exprimûˋ avec moins de bits. Le plancher de bruit ne peut ûˆtre relevûˋ que pour les frûˋquences auxquelles le masquage agit. Pour maximaliser le masquage actif, il faut dûˋcouper le spectre audio en diffûˋrentes bandes de frûˋquence pour permettre l'introduction des diffûˋrentes quantitûˋs de compression et de bruit dans chacune d'elles.
III. Codage en sous-bandes▲
La figure suivante montre un compresseur û bandes sûˋparûˋes. Le filtre sûˋparateur de bandes est un jeu de filtres û phase linûˋaire, ayant tous la mûˆme largeur de bande et qui se recouvrent. La sortie de chaque bande consiste en des ûˋchantillons reprûˋsentatifs de la forme d'onde. Dans chaque bande de frûˋquence, l'entrûˋe audio est amplifiûˋe au maximum avant la transmission. Chaque niveau est ensuite ramenûˋ û sa valeur initiale. Le bruit introduit par la transmission est ainsi rûˋduit dans chaque bande. Si l'on compare la rûˋduction de bruit au seuil d'audition, on s'aperûÏoit qu'un bruit plus important peut ûˆtre tolûˋrûˋ dans certaines bandes du fait de l'action du masquage. Par consûˋquent, il est possible, dans chaque bande, de rûˋduire la longueur des mots d'ûˋchantillons aprû´s la compression. Cette technique rûˋalise une compression parce que le bruit introduit par la perte de rûˋsolution est masquûˋ. La figure ci-dessous prûˋsente un codeur simple û bandes sûˋparûˋes, comme ceux utilisûˋs dans la Couche 1 du MPEG. L'entrûˋe audionumûˋrique alimente un filtre de sûˋparation de bandes qui divise le spectre du signal en un certain nombre de bandes.
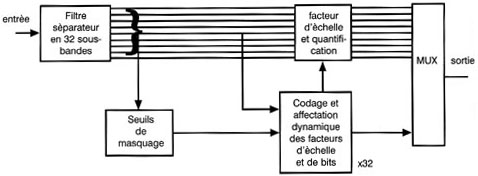
En MPEG, ce nombre est de 32. L'axe des temps est divisûˋ en blocs d'ûˋgale longueur. Dans la couche 1 de MPEG, il y a donc 384 ûˋchantillons du signal d'entrûˋe, ce qui se traduira, en sortie du filtre, par 12 ûˋchantillons dans chacune des 32 bandes. û l'intûˋrieur de chaque bande, le niveau est amplifiûˋ par multiplication jusqu'û sa valeur maximale. Le gain nûˋcessaire est constant pour la durûˋe du bloc et un seul facteur d'ûˋchelle est transmis avec chaque bloc, pour chaque bande, de faûÏon û pouvoir renverser le processus au dûˋcodage.
La sortie du groupe de filtres est ûˋgalement analysûˋe afin de dûˋterminer le spectre du signal d'entrûˋe. Cette analyse permet de rûˋaliser un modû´le de masquage permettant de dûˋterminer le degrûˋ de masquage que l'on peut attendre dans chaque bande. Dans chaque bande, plus le masquage est agissant, moins l'ûˋchantillon doit ûˆtre prûˋcis. La prûˋcision d'ûˋchantillon est alors rûˋduite par requantification en vue de diminuer la longueur des mots. Cette rûˋduction est aussi constante pour chaque mot dans la bande, mais les diffûˋrentes bandes peuvent utiliser des longueurs de mots diffûˋrentes. La longueur de mots doit ûˆtre transmise comme un code d'affectation de bits afin de permettre au dûˋcodeur de dûˋsûˋrialisûˋ convenablement le flux de bits.
III-A. Couche 1 du MPEG▲
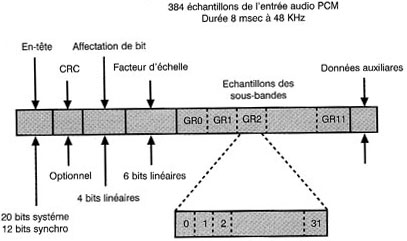
Aprû´s le mot de synchronisation et l'en-tûˆte, il y a 32 codes d'affectation de bits de 4 bits chacun. Ces codes dûˋcrivent la longueur des mots des ûˋchantillons dans chaque sous-bande. Viennent ensuite les 32 facteurs d'ûˋchelle utilisûˋs par la compression dans chaque bande. Ces facteurs d'ûˋchelle sont indispensables pour rûˋtablir le bon niveau au dûˋcodage. Les facteurs d'ûˋchelle sont suivis des donnûˋes audio de chaque bande.
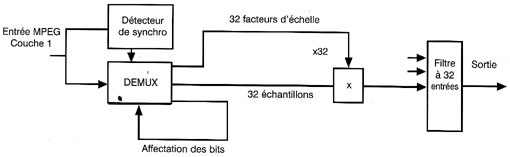
Le mot de synchronisation est dûˋtectûˋ par le gûˋnûˋrateur de temps qui dûˋsûˋrialise les bits d'affectation et les donnûˋes de facteur d'ûˋchelle. L'affectation de bits permet ensuite la dûˋsûˋrialisation des ûˋchantillons û longueurs variables. La requantification inverse et la multiplication par l'inverse du facteur de compression sont appliquûˋes de faûÏon û ramener le niveau de chaque bande û sa bonne valeur. Les 32 bandes sont ensuite rassemblûˋes dans un filtre de recombinaison pour rûˋtablir la sortie audio.
III-B. Couche 2 du MPEG▲
Cette figure montre que, lorsque le filtre de sûˋparation de bandes est utilisûˋ pour crûˋer le modû´le de masquage, l'analyse de spectre n'est pas trû´s prûˋcise dans la mesure oû¿ il n'y a que 32 sous-bandes et que l'ûˋnergie est rûˋpartie dans la totalitûˋ de la bande. On ne peut pas trop augmenter le plancher de bruit car, dans le pire des cas, le masquage n'agirait pas. Une analyse spectrale plus prûˋcise autoriserait un facteur de compression plus ûˋlevûˋ. Dans la couche 2 du MPEG, l'analyse spectrale est effectuûˋe û l'aide d'un processus sûˋparûˋ.
Une FFT û 512 points est effectuûˋe directement û partir du signal d'entrûˋe pour le modû´le de masquage. Pour amûˋliorer la prûˋcision de la rûˋsolution de frûˋquence, il faut augmenter l'excursion temporelle de la transformûˋe, ce qui est effectuûˋ en portant la taille du bloc û 1152 ûˋchantillons. Bien que le synoptique de la compression de blocs soit identique û celui de la couche 1 du MPEG, tous les facteurs d'ûˋchelle ne sont pas transmis dans la mesure oû¿, dans les images de programme, ils prûˋsentent un degrûˋ de redondance non nûˋgligeable.
Le facteur d'ûˋchelle de blocs successifs excû´de 2dB dans moins de 10ô % des cas et on a avantage û tirer parti de cette caractûˋristique en analysant les groupes de trois facteurs d'ûˋchelle successifs. Sur les programmes fixes, seul un facteur d'ûˋchelle sur trois est transmis. û mesure de l'augmentation de la variation dans une bande donnûˋe, deux ou trois facteurs d'ûˋchelle sont transmis. Un code de sûˋlection est ûˋgalement transmis pour permettre au dûˋcodeur de dûˋterminer ce qui a ûˋtûˋ ûˋmis dans chaque bande. Cette technique permet de diviser par deux le dûˋbit du facteur d'ûˋchelle.
IV. Codage de transformûˋe▲
Les couches 1 et 2 du MPEG sont basûˋes sur les filtres sûˋparateurs de bandes dans lesquels le signal est toujours reprûˋsentûˋ comme une forme d'onde. La couche 3 utilise de son cûÇtûˋ un codage de transformûˋe comme celui utilisûˋ en vidûˋo. Comme indiquûˋ plus haut, l'oreille effectue une espû´ce de transformûˋe sur le son incident et, du fait du facteur de rûˋsonance Q de la membrane basilaire, la rûˋponse ne peut augmenter ou diminuer rapidement. Par consûˋquent, si un signal audio est transformûˋ dans le domaine frûˋquentiel, il n'est plus nûˋcessaire de transmettre les coefficients trop souvent. Ce principe constitue la base du codage de transformûˋe. Pour des facteurs de compression plus ûˋlevûˋs, les coefficients peuvent ûˆtre requantifiûˋs, ce qui les rend moins prûˋcis. Ce processus gûˋnû´re du bruit qui pourra ûˆtre placûˋ û des frûˋquences oû¿ le masquage est le plus fort. Une caractûˋristique secondaire d'un codeur de transformûˋe est donc que le spectre d'entrûˋe est connu trû´s prûˋcisûˋment, ce qui permet de crûˋer un modû´le de masquage trû´s fidû´le.
IV-A. Couche 3 du MPEG▲
Ce niveau complexe de codage n'est en rûˋalitûˋ utilisûˋ que lorsque les facteurs de compression les plus ûˋlevûˋs sont nûˋcessaires. Il comporte quelques points communs avec la couche 2. Une transformûˋe cosinus discrû´te û 384 coefficients de sortie par bloc est utilisûˋe. On peut obtenir ce rûˋsultat par un traitement direct des ûˋchantillons d'entrûˋe, mais, dans un codeur multiniveau, il est possible d'utiliser une transformûˋe hybride incorporant le filtrage 32 bandes des couches 1 et 2. Dans ce cas, les 32 sous-bandes du filtre QMF (Quadrature Mirror Filter) sont ensuite traitûˋes par une Transformûˋe Cosinus Discrû´te Modifiûˋe (Modified Discrete Cosine Transform) û 32 bandes pour obtenir les 384 coefficients. Deux tailles de fenûˆtres sont utilisûˋes pour ûˋviter les prûˋoscillations û la transmission. La commutation de fenûˆtres est commandûˋe par le modû´le psychoacoustique. On a trouvûˋ que le prûˋûˋcho n'apparaissait dans l'entropie que lorsqu'elle ûˋtait supûˋrieure au niveau moyen. Pour obtenir le facteur de compression le plus ûˋlevûˋ, une quantification non uniforme des coefficients est effectuûˋe selon le codage de Huffman. Cette technique attribue les mots les plus courts aux valeurs de code les plus frûˋquentes.
IV-B. Le codage AC-3▲
La technique de codage audio AC-3 est utilisûˋe avec le systû´me ATSC û la place d'un des systû´mes de codage audio MPEG. DVB a aussi dû£ l'adopter sous la pression des industriels. Le systû´me AC-3 est basûˋ sur une transformûˋe et obtient le gain de codage en requantifiant les coefficients de frûˋquence. L'entrûˋe PCM d'un codeur AC-3 est divisûˋe en blocs par des fenûˆtres qui se chevauchent comme indiquûˋ ci-dessous.
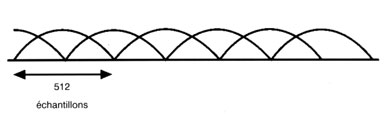
Ces blocs contiennent chacun 512 ûˋchantillons, mais, du fait du chevauchement total, il existe une redondance de 100ô %. Aprû´s la transformûˋe, il existe donc 512 coefficients qui peuvent, du fait de la redondance, ûˆtre ramenûˋs û 256 û l'aide d'une technique appelûˋe Suppression par aliasing dans le domaine temporel (TDAC, Time Domain Aliasing Cancelation).
La forme du signal d'entrûˋe est analysûˋe et, s'il existe une ûˋvolution significative dans la seconde moitiûˋ du bloc, le signal sera sûˋparûˋ en deux pour ûˋviter les prûˋûˋchos. Dans ce cas, le nombre de coefficients reste le mûˆme, mais la rûˋsolution de frûˋquence sera divisûˋe par deux et la rûˋsolution temporelle doublûˋe. Un indicateur (flag) est placûˋ dans le flux de bits pour signaler que cette opûˋration a ûˋtûˋ effectuûˋe. Les coefficients sont ûˋmis sous un format û virgule flottante avec une mantisse et un exposant. La reprûˋsentation est l'ûˋquivalent binaire de la notation scientifique.
Les exposants constituent en fait les facteurs d'ûˋchelle. Le jeu d'exposants d'un bloc produit l'analyse spectrale d'un signal d'entrûˋe avec une prûˋcision finie sur une ûˋchelle logarithmique appelûˋe enveloppe spectrale. Cette analyse spectrale est le signal d'entrûˋe du modû´le de masquage dûˋfinissant, pour chaque frûˋquence, le niveau jusqu'oû¿ le bruit peut ûˆtre augmentûˋ. Le modû´le de masquage pilote le processus de requantification qui diminue la prûˋcision de chaque coefficient en arrondissant la mantisse. Cette mantisse constitue une partie significative de la donnûˋe transmise. Les exposants sont ûˋgalement transmis, mais pas intûˋgralement dans la mesure oû¿ la redondance qu'ils comportent peut ûˆtre ultûˋrieurement exploitûˋe.
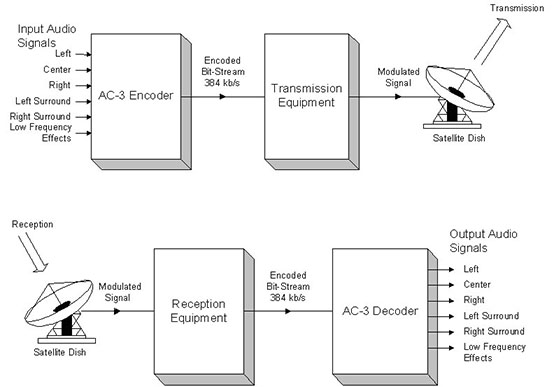
û l'intûˋrieur d'un bloc, seul le premier exposant (celui de la frûˋquence la plus basse) est transmis dans sa forme absolue. Les autres sont transmis de faûÏon diffûˋrentielle et le dûˋcodeur ajoute la diffûˋrence avec l'exposant prûˋcûˋdent. Quand le signal audio prûˋsente un spectre assez aplati, les exposants peuvent ûˆtre identiques pour plusieurs bandes de frûˋquences. Les exposants peuvent alors ûˆtre assemblûˋs en groupes de deux û quatre avec un indicateur dûˋcrivant leur mode de groupement. Des jeux de six blocs sont assemblûˋs dans une trame de synchro AC-3. Le premier bloc de la trame comporte la donnûˋe complû´te pour l'exposant, mais, dans le cas de signaux constants, les blocs suivants de la trame peuvent utiliser le mûˆme exposant. Voici un schûˋma du fonctionnement de l'encodeur AC-3ô :
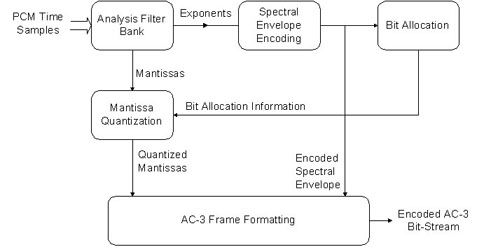
Alors que celui-ci dûˋmontre le fonctionnement du Dûˋcodeur AC-3ô :
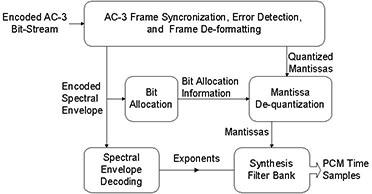
Le schûˋma suivant montre comment le signal AC-3 est transmis et reûÏu en DVBô :