I. Introduction▲
L'Audio Engineering Society (AES) et l'European Broadcasting Union (EBU) ont ĂŠtabli conjointement une norme audio numĂŠrique connue sous le terme d'interface AES/EBU. Cette norme propose des formats pour l'ĂŠchange d'informations audionumĂŠriques entre appareils audio professionnels, tout en garantissant la souplesse nĂŠcessaire aux applications spĂŠciales. L'International Electrotechnical Commission (IEC) a ĂŠgalement adoptĂŠ un format basĂŠ sur la norme AES/EBU pour les appareils audio grand public.
En bref, la norme de format AES/EBU dĂŠfinit comment deux canaux d'informations audio sont pĂŠriodiquement ĂŠchantillonnĂŠs et transmis sur une paire de fils torsadĂŠs. Les canaux audio gauche et droit sont multiplexĂŠs et sont autocadencĂŠs et autosynchronisĂŠs. Le format de mesure est indĂŠpendant de la frĂŠquence d'ĂŠchantillonnage recommandĂŠe par l'AES et supporte, sur 24 bits, 32 kHz, 44,1 kHz et 48 kHz.
 Ne jamais transmettre ce que l'on ne peut pas entendre. 
Cette compression audio, qui est entièrement basÊe sur les caractÊristiques de l'audition humaine, s'accompagne de pertes et ne peut être abordÊe sans une Êtude prÊalable de ce sens. Il est surprenant de constater que l'audition humaine, et particulièrement en stÊrÊo, a un pouvoir discriminatoire bien supÊrieur à celui de la vision et c'est pourquoi la compression audio doit être envisagÊe avec encore plus de prÊcautions. Comme la compression vidÊo, la compression audio nÊcessite plusieurs niveaux de complexitÊ en fonction du facteur de compression souhaitÊ.
Une autre considĂŠration importante dans l'enregistrement et la diffusion numĂŠrique d'aujourd'hui est le monitoring du ÂŤÂ point de crash  ou point d'atteinte du ÂŤÂ niveau d'entrĂŠe maximum  admissible par un système ou un ĂŠquipement. Le format d'enregistrement numĂŠrique est quelque peu plus tolĂŠrant, dans le sens oĂš quelques pointes ÂŤÂ hors tolĂŠrance  tombent simplement hors de la gamme de l'appareil numĂŠrique et ne sont pas ĂŠchantillonnĂŠes. Une sĂŠrie de ÂŤÂ pops  ou de ÂŤÂ sifflements  qui pourraient sĂŠrieusement compromettre un enregistrement analogique peuvent ĂŞtre automatiquement ÂŤÂ attĂŠnuĂŠs . Ce phĂŠnomène a entraĂŽnĂŠ quelques personnes vers la fausse notion que les niveaux audio numĂŠriques pouvaient ĂŞtre apprĂŠhendĂŠs de manière plus simpliste. Les appareils de mesure rudimentaires intĂŠgrĂŠs dans la plupart des appareils numĂŠriques reflètent cette attitude. Il est aussi nĂŠcessaire de produire un volume plus consistant dans les enregistrements numĂŠriques que dans les enregistrements analogiques. Avoir quelques prises ÂŤÂ plus fortes  que d'autres est plus acceptable dans le nouveau monde numĂŠrique que cela n'ĂŠtait dans l'environnement analogique. Il y a ĂŠgalement la mĂŞme nĂŠcessitĂŠ de protĂŠger les CRĂTES. L'idĂŠe qu'un ÂŤÂ certain nombre  de crashs soit tolĂŠrable est simplement fausse. Obtenir le volume au dĂŠtriment des crĂŞtes rĂŠsulte en une perte de dimension et de clartĂŠ.
II. Le mĂŠcanisme de l'audition▲
L'audition se compose d'un processus physique à l'intÊrieur de l'oreille et d'un processus nerveux et mental qui se combinent pour donner une impression sonore. L'impression que nous recevons n'est pas exactement similaire à la forme d'onde acoustique prÊsente dans le conduit auditif parce qu'une certaine entropie est perdue. Les systèmes de compression audio qui donneront de bons rÊsultats seront donc ceux qui ne perdront que la partie de l'entropie qui est perdue dans le mÊcanisme de l'audition.
Le mÊcanisme physique de l'audition se rÊpartit en trois parties : l'oreille externe, l'oreille moyenne et l'oreille interne. En plus du pavillon, l'oreille externe comprend le conduit auditif et le tympan. Le tympan transforme les sons incidents en une vibration comme le fait un diaphragme de microphone. L'oreille interne opère en utilisant ces vibrations transmises à travers un fluide. L'impÊdance du fluide est bien supÊrieure à celle de l'air et l'oreille moyenne agit comme un transformateur d'impÊdance qui effectue le transfert d'Ênergie.
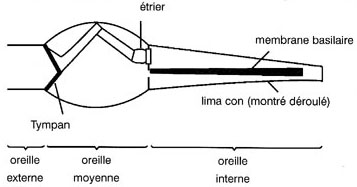
On voit ci-dessus que les vibrations sont transfÊrÊes à l'oreille interne par l'Êtrier, qui agit sur la fenêtre ovale. Les vibrations du fluide de l'oreille interne parviennent au limaçon, une cavitÊ du crâne en forme de spirale(prÊsentÊe dÊroulÊe sur la figure, pour plus de clartÊ). La membrane basilaire est ÊtirÊe sur toute la longueur du limaçon. Le poids et la consistance de cette membrane varient d'un bout à l'autre. Près de la fenêtre ovale, la membrane est rigide et lÊgère et sa frÊquence de rÊsonance est ÊlevÊe. à l'autre extrÊmitÊ, la membrane est lourde et souple, ce qui fait qu'elle rÊsonne aux frÊquences basses.
La gamme de frÊquences disponibles dÊtermine la plage de l'audition humaine qui, pour la plupart des gens, s'Êtend de 60 Hz à 15 Khz. Les diffÊrentes frÊquences du son incident provoquent la vibration de diffÊrentes parties de la membrane. Toutes les zones de la membrane sont reliÊes à diffÊrentes terminaisons nerveuses qui permettent une discrimination très fine. La membrane basilaire est Êgalement munie de fins muscles commandÊs par les nerfs et qui agissent ensemble dans une sorte de contre-rÊaction positive qui aurait tendance à augmenter le facteur de rÊsonance Q. Le comportement rÊsonnant de la membrane basilaire constitue une rÊplique exacte d'un analyseur de transformÊes.
En raison de la thÊorie de l'incertitude, plus le domaine de frÊquences d'un signal est connu, moins son domaine temporel est connu. En consÊquence, plus un système est apte à dÊterminer la diffÊrence entre deux frÊquences, moins il est capable de sÊparer le temps qui les sÊpare. L'audition humaine a dÊveloppÊ un certain compromis entre la discrimination incertitude temporelle et la discrimination de frÊquence, ce compromis impliquant qu'aucune perfection n'est atteinte. La discrimination imparfaite de frÊquences rÊsulte du fait de l'incapacitÊ de sÊparer deux frÊquences proches. Cette incapacitÊ est connue comme un effet de masquage auditif qui rÊduit la sensibilitÊ d'un son en prÊsence d'un autre. La figure 3.2a montre que le seuil d'audition est fonction de la frÊquence. La plus grande sensibilitÊ se situe naturellement dans la gamme de frÊquences de la parole.
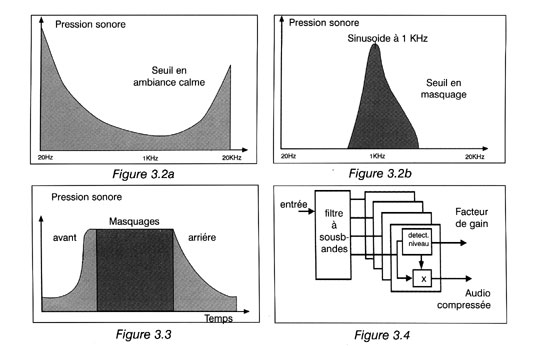
En prÊsence d'une note pure, le seuil est modifiÊ, tel qu'indiquÊ sur la figure 3.2b. Le seuil est relevÊ non seulement pour des frÊquences hautes, mais aussi pour quelques frÊquences basses. En prÊsence d'une source sonore au spectre plus complexe, comme de la musique, le seuil est relevÊ à presque toutes les frÊquences. Une consÊquence de ce comportement est que le sifflement d'une cassette audio n'est audible que pendant les passages très doux de la musique.
La compression utilise ce principe en amplifiant les frÊquences basses avant l'enregistrement ou la transmission et en les ramenant ultÊrieurement à leur niveau convenable. La discrimination imparfaite de temps montrÊe par l'oreille est due à sa rÊponse rÊsonante. Le facteur de rÊsonance Q est tel qu'il faut qu'un son donnÊ soit prÊsent au moins une milliseconde avant qu'il ne devienne audible. à cause de cette rÊponse lente, le masquage peut se produire même si les deux signaux concernÊs ne sont pas simultanÊs. Les masquages avant et arrière peuvent se produire quand le son de masquage continue à agir à des niveaux plus faibles avant et après la durÊe courante du son de masquage. La figure 3.3 dÊmontre ce concept. Le masquage relève le seuil d'audition et les systèmes de compression tirent parti de cet effet en rehaussant le niveau  plancher  de bruit, permettant ainsi au signal audio d'être exprimÊ avec moins de bits. Le plancher de bruit ne peut être relevÊ que pour les frÊquences auxquelles le masquage agit. Pour maximaliser le masquage actif, il faut dÊcouper le spectre audio en diffÊrentes bandes de frÊquence pour permettre l'introduction des diffÊrentes quantitÊs de compression et de bruit dans chacune d'elles.
III. Codage en sous-bandes▲
La figure suivante montre un compresseur à bandes sÊparÊes. Le filtre sÊparateur de bandes est un jeu de filtres à phase linÊaire, ayant tous la même largeur de bande et qui se recouvrent. La sortie de chaque bande consiste en des Êchantillons reprÊsentatifs de la forme d'onde. Dans chaque bande de frÊquence, l'entrÊe audio est amplifiÊe au maximum avant la transmission. Chaque niveau est ensuite ramenÊ à sa valeur initiale. Le bruit introduit par la transmission est ainsi rÊduit dans chaque bande. Si l'on compare la rÊduction de bruit au seuil d'audition, on s'aperçoit qu'un bruit plus important peut être tolÊrÊ dans certaines bandes du fait de l'action du masquage. Par consÊquent, il est possible, dans chaque bande, de rÊduire la longueur des mots d'Êchantillons après la compression. Cette technique rÊalise une compression parce que le bruit introduit par la perte de rÊsolution est masquÊ. La figure ci-dessous prÊsente un codeur simple à bandes sÊparÊes, comme ceux utilisÊs dans la Couche 1 du MPEG. L'entrÊe audionumÊrique alimente un filtre de sÊparation de bandes qui divise le spectre du signal en un certain nombre de bandes.
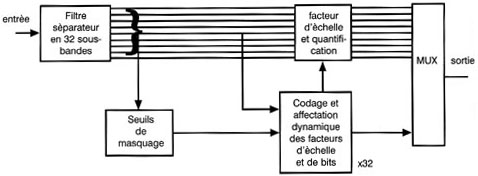
En MPEG, ce nombre est de 32. L'axe des temps est divisÊ en blocs d'Êgale longueur. Dans la couche 1 de MPEG, il y a donc 384 Êchantillons du signal d'entrÊe, ce qui se traduira, en sortie du filtre, par 12 Êchantillons dans chacune des 32 bandes. à l'intÊrieur de chaque bande, le niveau est amplifiÊ par multiplication jusqu'à sa valeur maximale. Le gain nÊcessaire est constant pour la durÊe du bloc et un seul facteur d'Êchelle est transmis avec chaque bloc, pour chaque bande, de façon à pouvoir renverser le processus au dÊcodage.
La sortie du groupe de filtres est Êgalement analysÊe afin de dÊterminer le spectre du signal d'entrÊe. Cette analyse permet de rÊaliser un modèle de masquage permettant de dÊterminer le degrÊ de masquage que l'on peut attendre dans chaque bande. Dans chaque bande, plus le masquage est agissant, moins l'Êchantillon doit être prÊcis. La prÊcision d'Êchantillon est alors rÊduite par requantification en vue de diminuer la longueur des mots. Cette rÊduction est aussi constante pour chaque mot dans la bande, mais les diffÊrentes bandes peuvent utiliser des longueurs de mots diffÊrentes. La longueur de mots doit être transmise comme un code d'affectation de bits afin de permettre au dÊcodeur de dÊsÊrialisÊ convenablement le flux de bits.
III-A. Couche 1 du MPEG▲
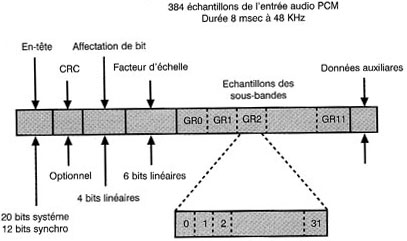
Après le mot de synchronisation et l'en-tête, il y a 32 codes d'affectation de bits de 4 bits chacun. Ces codes dÊcrivent la longueur des mots des Êchantillons dans chaque sous-bande. Viennent ensuite les 32 facteurs d'Êchelle utilisÊs par la compression dans chaque bande. Ces facteurs d'Êchelle sont indispensables pour rÊtablir le bon niveau au dÊcodage. Les facteurs d'Êchelle sont suivis des donnÊes audio de chaque bande.
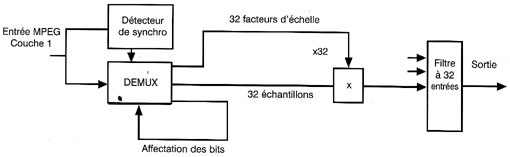
Le mot de synchronisation est dÊtectÊ par le gÊnÊrateur de temps qui dÊsÊrialise les bits d'affectation et les donnÊes de facteur d'Êchelle. L'affectation de bits permet ensuite la dÊsÊrialisation des Êchantillons à longueurs variables. La requantification inverse et la multiplication par l'inverse du facteur de compression sont appliquÊes de façon à ramener le niveau de chaque bande à sa bonne valeur. Les 32 bandes sont ensuite rassemblÊes dans un filtre de recombinaison pour rÊtablir la sortie audio.
III-B. Couche 2 du MPEG▲
Cette figure montre que, lorsque le filtre de sÊparation de bandes est utilisÊ pour crÊer le modèle de masquage, l'analyse de spectre n'est pas très prÊcise dans la mesure oÚ il n'y a que 32 sous-bandes et que l'Ênergie est rÊpartie dans la totalitÊ de la bande. On ne peut pas trop augmenter le plancher de bruit car, dans le pire des cas, le masquage n'agirait pas. Une analyse spectrale plus prÊcise autoriserait un facteur de compression plus ÊlevÊ. Dans la couche 2 du MPEG, l'analyse spectrale est effectuÊe à l'aide d'un processus sÊparÊ.
Une FFT à 512 points est effectuÊe directement à partir du signal d'entrÊe pour le modèle de masquage. Pour amÊliorer la prÊcision de la rÊsolution de frÊquence, il faut augmenter l'excursion temporelle de la transformÊe, ce qui est effectuÊ en portant la taille du bloc à 1152 Êchantillons. Bien que le synoptique de la compression de blocs soit identique à celui de la couche 1 du MPEG, tous les facteurs d'Êchelle ne sont pas transmis dans la mesure oÚ, dans les images de programme, ils prÊsentent un degrÊ de redondance non nÊgligeable.
Le facteur d'Êchelle de blocs successifs excède 2dB dans moins de 10 % des cas et on a avantage à tirer parti de cette caractÊristique en analysant les groupes de trois facteurs d'Êchelle successifs. Sur les programmes fixes, seul un facteur d'Êchelle sur trois est transmis. à mesure de l'augmentation de la variation dans une bande donnÊe, deux ou trois facteurs d'Êchelle sont transmis. Un code de sÊlection est Êgalement transmis pour permettre au dÊcodeur de dÊterminer ce qui a ÊtÊ Êmis dans chaque bande. Cette technique permet de diviser par deux le dÊbit du facteur d'Êchelle.
IV. Codage de transformĂŠe▲
Les couches 1 et 2 du MPEG sont basÊes sur les filtres sÊparateurs de bandes dans lesquels le signal est toujours reprÊsentÊ comme une forme d'onde. La couche 3 utilise de son côtÊ un codage de transformÊe comme celui utilisÊ en vidÊo. Comme indiquÊ plus haut, l'oreille effectue une espèce de transformÊe sur le son incident et, du fait du facteur de rÊsonance Q de la membrane basilaire, la rÊponse ne peut augmenter ou diminuer rapidement. Par consÊquent, si un signal audio est transformÊ dans le domaine frÊquentiel, il n'est plus nÊcessaire de transmettre les coefficients trop souvent. Ce principe constitue la base du codage de transformÊe. Pour des facteurs de compression plus ÊlevÊs, les coefficients peuvent être requantifiÊs, ce qui les rend moins prÊcis. Ce processus gÊnère du bruit qui pourra être placÊ à des frÊquences oÚ le masquage est le plus fort. Une caractÊristique secondaire d'un codeur de transformÊe est donc que le spectre d'entrÊe est connu très prÊcisÊment, ce qui permet de crÊer un modèle de masquage très fidèle.
IV-A. Couche 3 du MPEG▲
Ce niveau complexe de codage n'est en rÊalitÊ utilisÊ que lorsque les facteurs de compression les plus ÊlevÊs sont nÊcessaires. Il comporte quelques points communs avec la couche 2. Une transformÊe cosinus discrète à 384 coefficients de sortie par bloc est utilisÊe. On peut obtenir ce rÊsultat par un traitement direct des Êchantillons d'entrÊe, mais, dans un codeur multiniveau, il est possible d'utiliser une transformÊe hybride incorporant le filtrage 32 bandes des couches 1 et 2. Dans ce cas, les 32 sous-bandes du filtre QMF (Quadrature Mirror Filter) sont ensuite traitÊes par une TransformÊe Cosinus Discrète ModifiÊe (Modified Discrete Cosine Transform) à 32 bandes pour obtenir les 384 coefficients. Deux tailles de fenêtres sont utilisÊes pour Êviter les prÊoscillations à la transmission. La commutation de fenêtres est commandÊe par le modèle psychoacoustique. On a trouvÊ que le prÊÊcho n'apparaissait dans l'entropie que lorsqu'elle Êtait supÊrieure au niveau moyen. Pour obtenir le facteur de compression le plus ÊlevÊ, une quantification non uniforme des coefficients est effectuÊe selon le codage de Huffman. Cette technique attribue les mots les plus courts aux valeurs de code les plus frÊquentes.
IV-B. Le codage AC-3▲
La technique de codage audio AC-3 est utilisÊe avec le système ATSC à la place d'un des systèmes de codage audio MPEG. DVB a aussi dÝ l'adopter sous la pression des industriels. Le système AC-3 est basÊ sur une transformÊe et obtient le gain de codage en requantifiant les coefficients de frÊquence. L'entrÊe PCM d'un codeur AC-3 est divisÊe en blocs par des fenêtres qui se chevauchent comme indiquÊ ci-dessous.
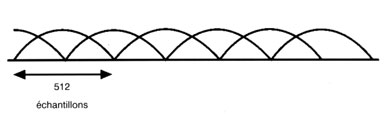
Ces blocs contiennent chacun 512 Êchantillons, mais, du fait du chevauchement total, il existe une redondance de 100 %. Après la transformÊe, il existe donc 512 coefficients qui peuvent, du fait de la redondance, être ramenÊs à 256 à l'aide d'une technique appelÊe Suppression par aliasing dans le domaine temporel (TDAC, Time Domain Aliasing Cancelation).
La forme du signal d'entrĂŠe est analysĂŠe et, s'il existe une ĂŠvolution significative dans la seconde moitiĂŠ du bloc, le signal sera sĂŠparĂŠ en deux pour ĂŠviter les prĂŠĂŠchos. Dans ce cas, le nombre de coefficients reste le mĂŞme, mais la rĂŠsolution de frĂŠquence sera divisĂŠe par deux et la rĂŠsolution temporelle doublĂŠe. Un indicateur (flag) est placĂŠ dans le flux de bits pour signaler que cette opĂŠration a ĂŠtĂŠ effectuĂŠe. Les coefficients sont ĂŠmis sous un format Ă virgule flottante avec une mantisse et un exposant. La reprĂŠsentation est l'ĂŠquivalent binaire de la notation scientifique.
Les exposants constituent en fait les facteurs d'Êchelle. Le jeu d'exposants d'un bloc produit l'analyse spectrale d'un signal d'entrÊe avec une prÊcision finie sur une Êchelle logarithmique appelÊe enveloppe spectrale. Cette analyse spectrale est le signal d'entrÊe du modèle de masquage dÊfinissant, pour chaque frÊquence, le niveau jusqu'oÚ le bruit peut être augmentÊ. Le modèle de masquage pilote le processus de requantification qui diminue la prÊcision de chaque coefficient en arrondissant la mantisse. Cette mantisse constitue une partie significative de la donnÊe transmise. Les exposants sont Êgalement transmis, mais pas intÊgralement dans la mesure oÚ la redondance qu'ils comportent peut être ultÊrieurement exploitÊe.
à l'intÊrieur d'un bloc, seul le premier exposant (celui de la frÊquence la plus basse) est transmis dans sa forme absolue. Les autres sont transmis de façon diffÊrentielle et le dÊcodeur ajoute la diffÊrence avec l'exposant prÊcÊdent. Quand le signal audio prÊsente un spectre assez aplati, les exposants peuvent être identiques pour plusieurs bandes de frÊquences. Les exposants peuvent alors être assemblÊs en groupes de deux à quatre avec un indicateur dÊcrivant leur mode de groupement. Des jeux de six blocs sont assemblÊs dans une trame de synchro AC-3. Le premier bloc de la trame comporte la donnÊe complète pour l'exposant, mais, dans le cas de signaux constants, les blocs suivants de la trame peuvent utiliser le même exposant. Voici un schÊma du fonctionnement de l'encodeur AC-3 :
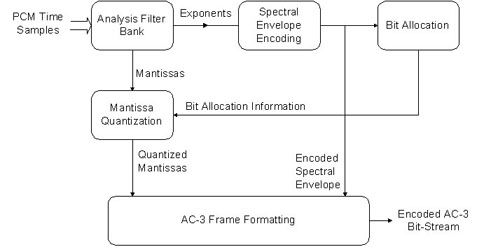
Alors que celui-ci dĂŠmontre le fonctionnement du DĂŠcodeur AC-3Â :
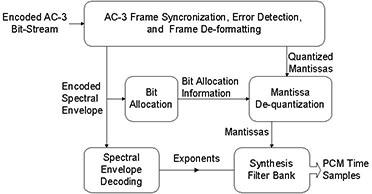
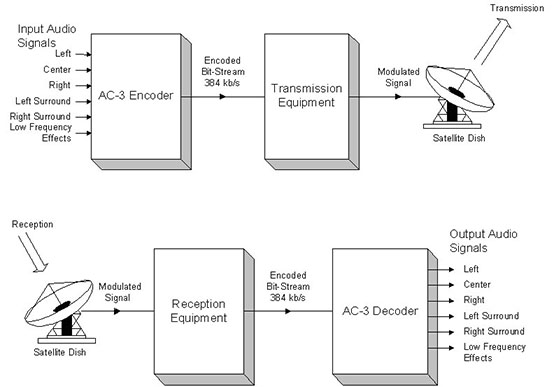
Le schÊma suivant montre comment le signal AC-3 est transmis et reçu en DVB :